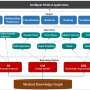
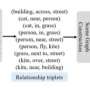
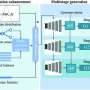
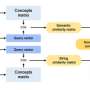
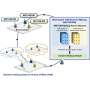
The framework uses a combination of superficial similarities to kickstart the machine learning process that produces aligned entity pairs. Credit: Tingting Jiang et al.
A team of researchers led by professor Xindong Wu in Hefei, China has developed an unsupervised entity alignment framework to improve the process of searching for related information in multiple knowledge graphs for artificial intelligence applications. The framework brings together the advantages of multiple approaches and avoids relying on human labor to kickstart the alignment process.
They tested their framework on several cross-lingual datasets and measured the results, comparing them against the results of 14 other machine learning algorithms. Their model outperformed most of its competitors on two different metrics, and scored better than all of them when the metrics were combined into an overall score.
The group's research was published in the journal Intelligent Computing.
The new framework, called SE-UEA, scored higher on precision and recall than 12 of 14 competing algorithms, some supervised and some unsupervised. It scored higher overall for all three datasets. Experiments testing the framework's robustness and scalability also achieved encouraging results.
A major advantage of the new framework is that it does not require complex datasets laboriously annotated by humans. It can automatically handle datasets with missing information and merge datasets that have different internal structure. The quantitative research results thus show that it is not just convenient but also effective to use a combination of relatively straightforward automatic methods of processing knowledge graphs to bootstrap a more sophisticated one.
Future research can further improve the efficiency and accuracy of the framework by tweaking one or the other of the framework's two modules.
The two modules of the framework are one that looks for surface similarities and another that looks for similarities in the relationships between entities. Both make use of a pair of knowledge graphs. In this case, the pair consisted of knowledge graphs for the same content in two different languages, English and Japanese, French or Chinese. The datasets were built by DBpedia from Wikipedia content.
The first module looks for not one but three different kinds of surface similarities: same name, same meaning and same location in the two knowledge graphs. Importantly, the output of this module is used as the input for the second module, which uses a type of neural network called a graph convolutional network to automatically examine the internal structure of the two knowledge graphs to discover pairs of identical entities.
After the framework analyzed each pair of knowledge graphs and produced pairs of identical entities, the researchers were able to check its work against the correct answers supplied as part of the DBpedia datasets and assign scores according to their chosen evaluation metrics.
Although knowledge graphs are critical for artificial intelligence applications such as recommendation systems, every structured representation of knowledge is generally incomplete. Thus it is desirable to combine information from multiple knowledge graphs via a process called entity alignment.
The most straightforward matching method is to compare surface attributes such as the names of the entities. More sophisticated methods achieve better results, but typically require elaborate input data which must first be created manually.
Wu's co-authors on this paper are Tingting Jiang (who was Wu's Ph.D. student), Chenyang Bu and Yi Zhu.
More information: Tingting Jiang et al, Integrating Symbol Similarities with Knowledge Graph Embedding for Entity Alignment: An Unsupervised Framework, Intelligent Computing (2023). DOI: 10.34133/icomputing.0021
Provided by Intelligent Computing